svadhyay — an AI tutor on a stack i fully control
three months, solo, no third-party AI APIs. why self-hosting was the whole point — and what it cost.
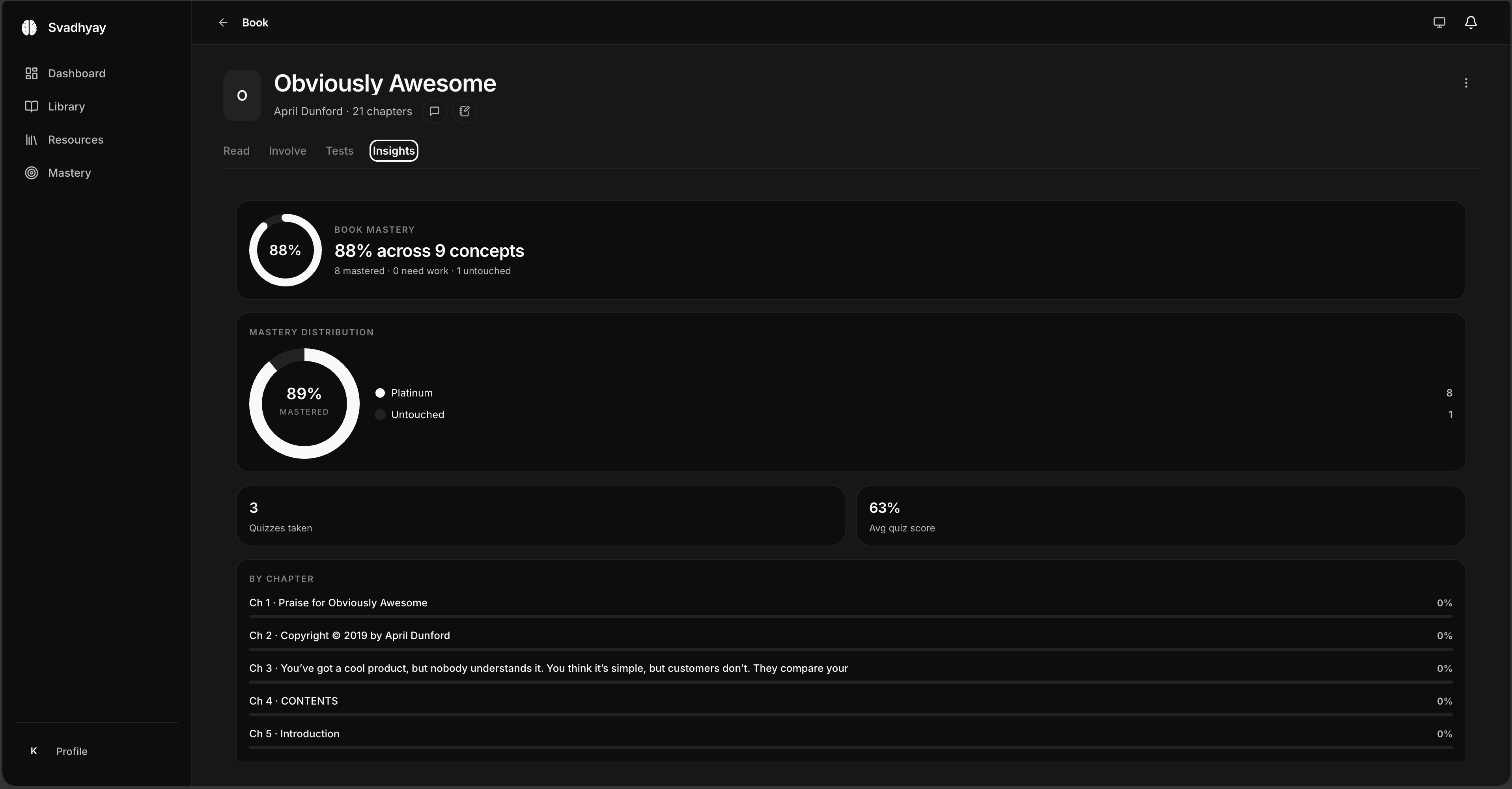
svadhyay is an AI tutor. multi-agent tutoring, illustrations generated on the fly, worksheets graded against a rubric — all grounded in real textbooks. i built it end-to-end in three months. closed beta, real users.
the constraint i set on day one: no third-party AI APIs. every model runs on infrastructure i control. that one rule shaped everything after it.
it isn't a chatbot
the obvious question in 2026: isn't an "AI tutor" just chatgpt with a system prompt? no — and the difference is the whole point.
a general assistant — chatgpt, claude, the same models i build with every day — answers from its weights. you bring the context, it improvises, and it forgets you the moment you close the tab. that's the wrong shape for learning. a tutor that confidently invents a fact is worse than no tutor; one with no memory of what you struggled with last week isn't teaching — it's just answering.
svadhyay is built the other way around:
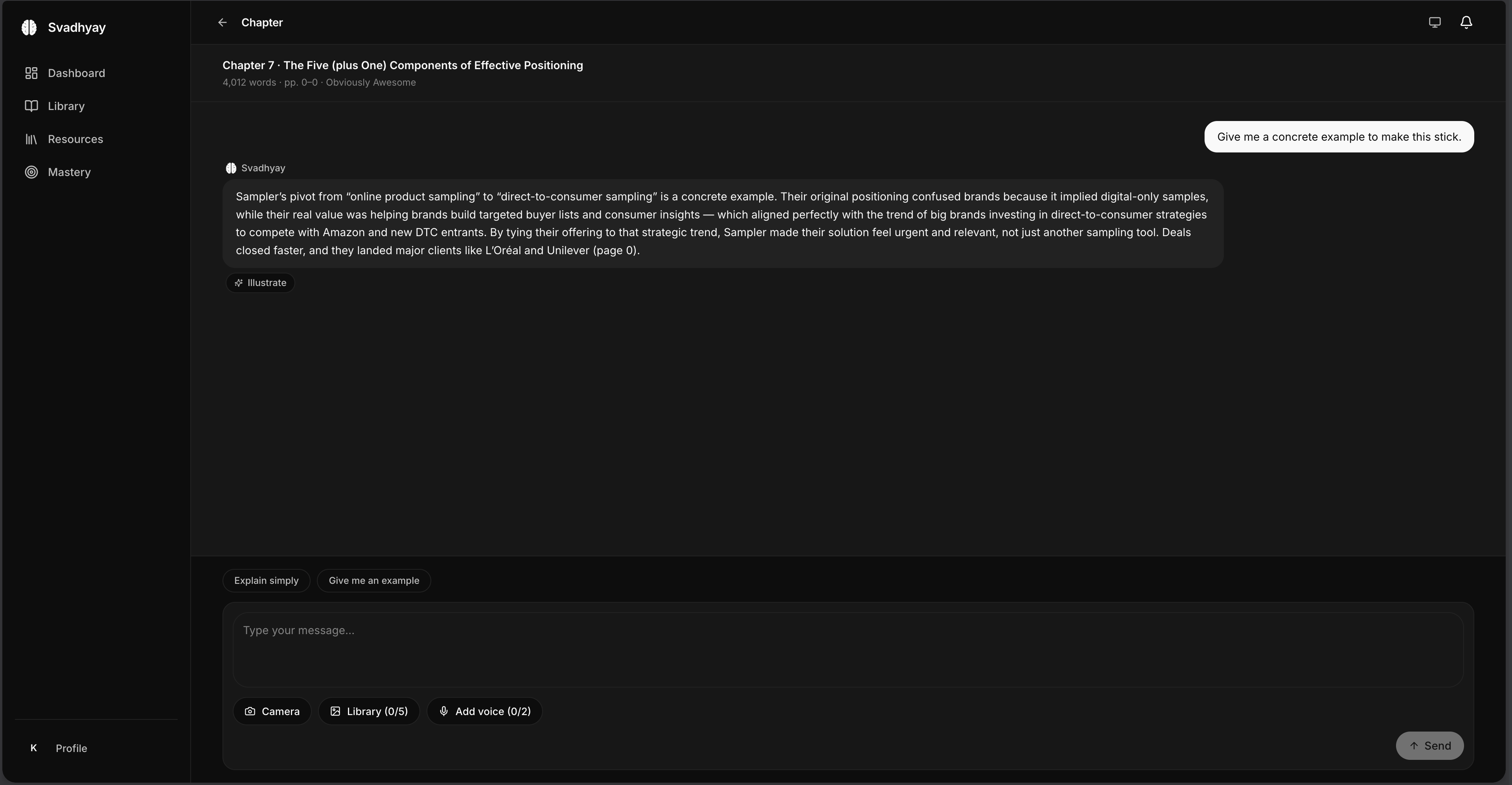
- grounded in your books, not the open web. every answer comes from the chapter you're actually reading, traced back to the page. it would rather say "that isn't in here" than make something up.
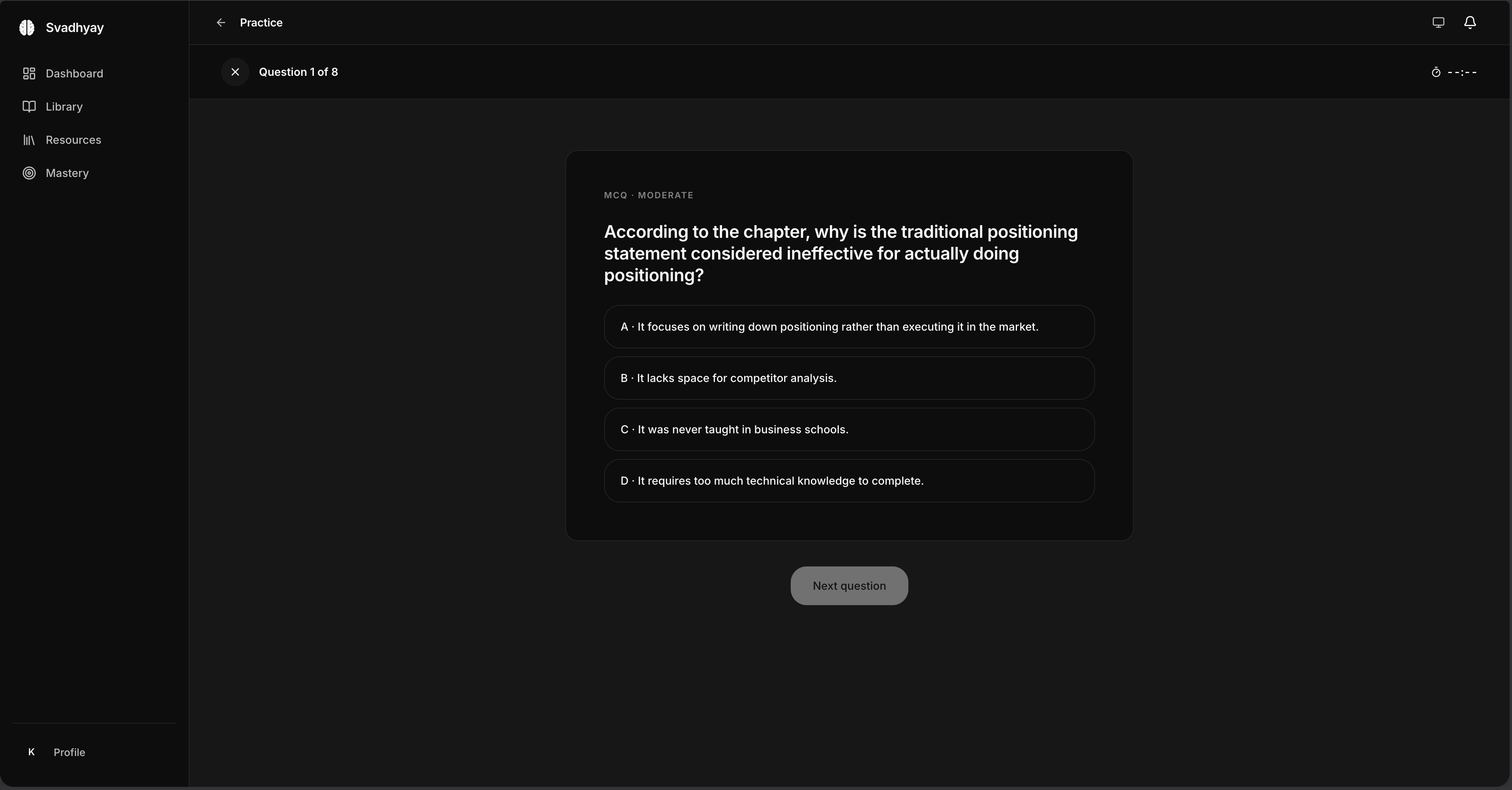
- it keeps a model of you. it tracks what you've mastered, concept by concept, and what you haven't — and aims quizzes and review at the gaps. the corpus is fixed; the thing that changes is you.
- it's a loop, not a prompt box. read → ask → quiz → mastery → revisit. agents with jobs — tutor, illustrator, evaluator — moving you through the material instead of waiting for your next question.
a chatbot is a brilliant generalist you have to drive. this is a narrow system that drives you through one book until you know it.
why self-host
three reasons, in the order they mattered:
- cost has no ceiling on someone else's API. a tutor that draws illustrations and grades worksheets makes a lot of model calls per session. per-token pricing makes usage a variable cost you can't cap. owned inference makes it a fixed one.
- the data doesn't leave. student work, textbook content — none of it goes to a vendor. for anyone with data-residency or GDPR constraints, that's not a nice-to-have. it's the line between shipping and not shipping at all.
- it runs anywhere. no vendor account, no rate limit, no model getting deprecated out from under me. the whole thing is portable.
the stack
| layer | what runs |
|---|---|
| LLM | qwen-3.5 |
| embeddings | BGE-large |
| speech-to-text | whisper |
| images | qwen-image |
| voice | TTS |
all self-hosted. orchestrated from a go + python backend on kubernetes.
the shape
clients react native (mobile) next.js (web + admin)
|
| grpc / http
v
app plane +------------+ +--------------+ +---------------------+
(go + | agentic | | rag ingest | | async job substrate |
python, | core | | + retrieval | | grpc + redis pubsub |
k8s) | (langgraph)| | pdf/epub/docx| | + custom job sdk |
+-----+------+ +------+-------+ +----------+----------+
| | |
v v v
model plane qwen-3.5 · BGE-large · whisper · qwen-image · TTS
(self-hosted)the hard parts
holding p99 under 10 seconds
self-hosted means the latency budget is yours to blow. there's no managed endpoint quietly autoscaling behind you. with an LLM, an embedder, an STT model, an image model and TTS all in the path, the naive version spends a minute thinking out loud.
the fix was an async job substrate — grpc + redis pubsub + a small custom job SDK — so long-running inference never sits on the request path. the request returns; the work continues; the client gets pushed the result. p99 ended up under ten seconds end-to-end.
keeping the agents on-rails
the agentic core is langgraph — separate agents for tutoring, illustration, and worksheet evaluation, coordinating through tool calls and structured outputs. the difference between a demo that works once and something a child opens every day is that the agent doesn't wander. structured outputs and tight tool contracts are how you buy that. most of the work here was constraining the model, not prompting it.
rag that actually grounds
multi-format ingestion — pdf, epub, docx — into a single retrieval corpus. chunking tuned to how textbooks are actually laid out, not a generic character split. pgvector for retrieval. the bar was answers that cite the page, not answers that merely sound right. for a tutor, a confident wrong answer is worse than no answer.
one machine, me
mobile in react native. web and admin in next.js. the go + python services. e2e in playwright. deploy through a cloudflared tunnel. no team — every layer was a call i made and then had to live with.
the surface area of a product like this hasn't shrunk. the team that builds it has.
what it left me with
a working AI tutor, in real hands — and a self-hosted LLM stack i now know how to stand up, tune, and keep inside a latency budget without renting it from anyone.